![[ICCV 2021] Dense Video Captioning with Parallel Decoding](https://www.emigroup.tech/wp-content/uploads/2021/08/图片1-840x420.png)
Teng Wang et al.
Abstract:
Dense video captioning aims to generate multiple associated captions with their temporal locations from the video. Previous methods follow a sophisticated “localize-then-describe” scheme, which heavily relies on numerous hand-crafted components. In this paper, we proposed a simple yet effective framework for end-to-end dense video captioning with parallel decoding (PDVC), by formulating the dense caption generation as a set prediction task. In practice, through stacking a newly proposed event counter on the top of a transformer decoder, the PDVC precisely segments the video into a number of event pieces under the holistic understanding of the video content, which effectively increases the coherence and readability of predicted captions. Compared with prior arts, the PDVC has several appealing advantages: (1) Without relying on heuristic non-maximum suppression or a recurrent event sequence selection network to remove redundancy, PDVC directly produces an event set with an appropriate size; (2) In contrast to adopting the two-stage scheme, we feed the enhanced representations of event queries into the localization head and caption head in parallel, making these two sub-tasks deeply interrelated and mutually promoted through the optimization; (3) Without bells and whistles, extensive experiments on ActivityNet Captions and YouCook2 show that PDVC is capable of producing high-quality captioning results, surpassing the state-of-the-art two-stage methods when its localization accuracy is on par with them. [Source Code].
Results
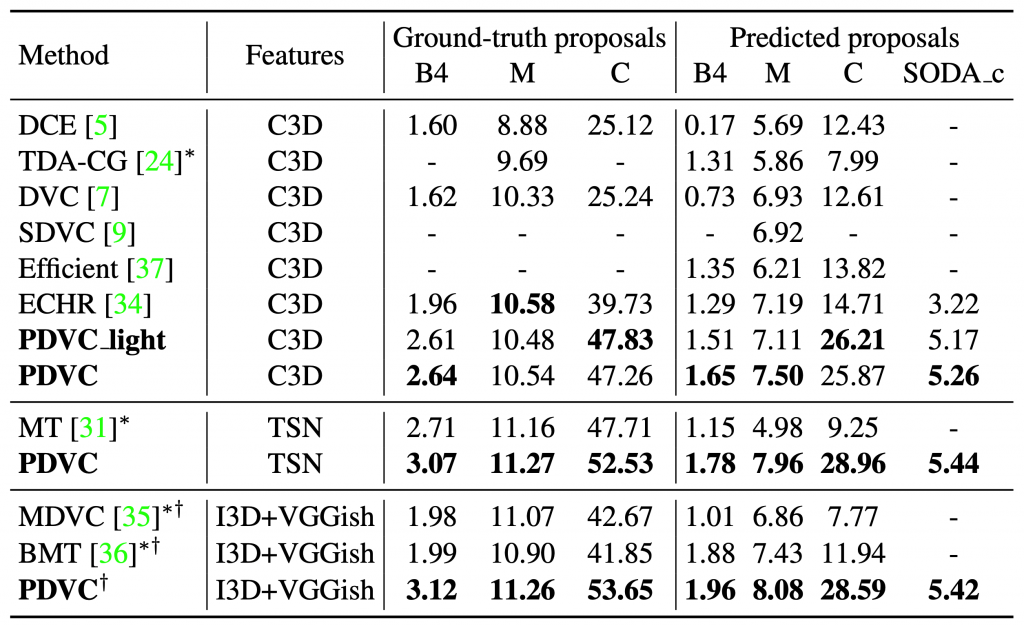
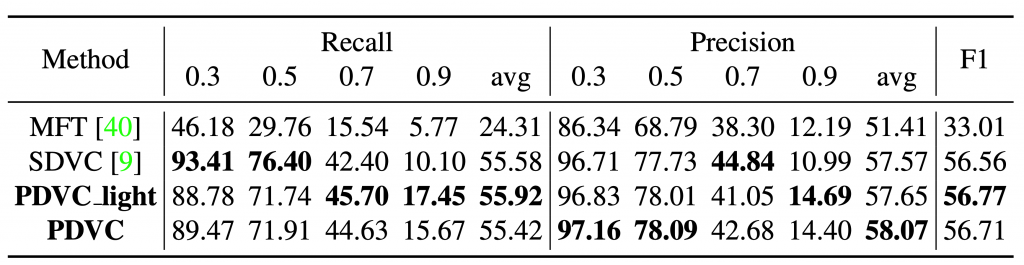
Performance on ActivityNet Captions
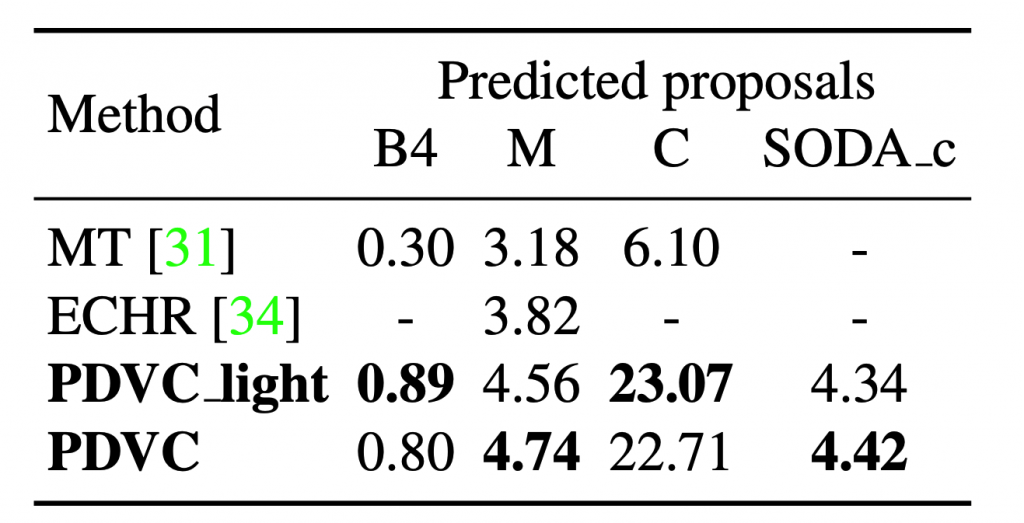
Performance on YouCook2
Visualization

Acknowledgments
This work was supported by the National Natural Science Foundation of China No. 61972188, 61903178, 61906081, and U20A20306, the General Research Fund of Hong Kong No. 27208720, and the Program for Guangdong Introducing Innovative and Enterpreneurial Teams No. 2017ZT07X386.
Citation
@article{wang2021end,
title={End-to-End Dense Video Captioning with Parallel Decoding},
author={Wang, Teng and Zhang, Ruimao and Lu, Zhichao and Zheng, Feng and Cheng, Ran and Luo, Ping},
journal={arXiv preprint},
year={2021}