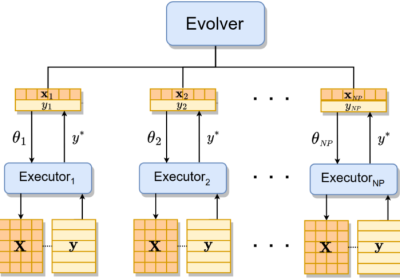
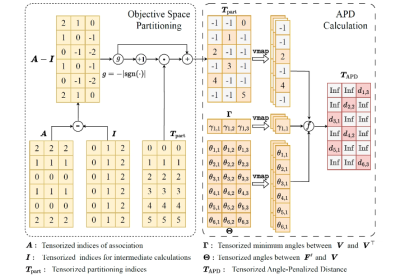
![[IEEE TEVC] EvoX: A Distributed GPU-accelerated Framework for Scalable Evolutionary Computation](https://www.emigroup.tech/wp-content/uploads/2024/04/EVXO-840x420.png)
Beichen Huang, Ran Cheng, Zhuozhao Li, Yaochu Jin, Kay Chen Tan
Abstract:
Inspired by natural evolutionary processes, Evolutionary Computation (EC) has established itself as a cornerstone of Artificial Intelligence. Recently, with the surge in data-intensive applications and large-scale complex systems, the demand for scalable EC solutions has grown significantly. However, most existing EC infrastructures fall short of catering to the heightened demands of large-scale problem solving. While the advent of some pioneering GPU-accelerated EC libraries is a step forward, they also grapple with some limitations, particularly in terms of flexibility and architectural robustness. In response, we introduce EvoX: a computing framework tailored for automated, distributed, and heterogeneous execution of EC algorithms. At the core of EvoX lies a unique programming model to streamline the development of parallelizable EC algorithms, complemented by a computation model specifically optimized for distributed GPU acceleration. Building upon this foundation, we have crafted an extensive library comprising a wide spectrum of 50+ EC algorithms for both single- and multi-objective optimization. Furthermore, the library offers comprehensive support for a diverse set of benchmark problems, ranging from dozens of numerical test functions to hundreds of reinforcement learning tasks. Through extensive experiments across a range of problem scenarios and hardware configurations, EvoX demonstrates robust system and model performances. EvoX is open-source and accessible at: https://github.com/EMI-Group/evox.
A Brief Introduction
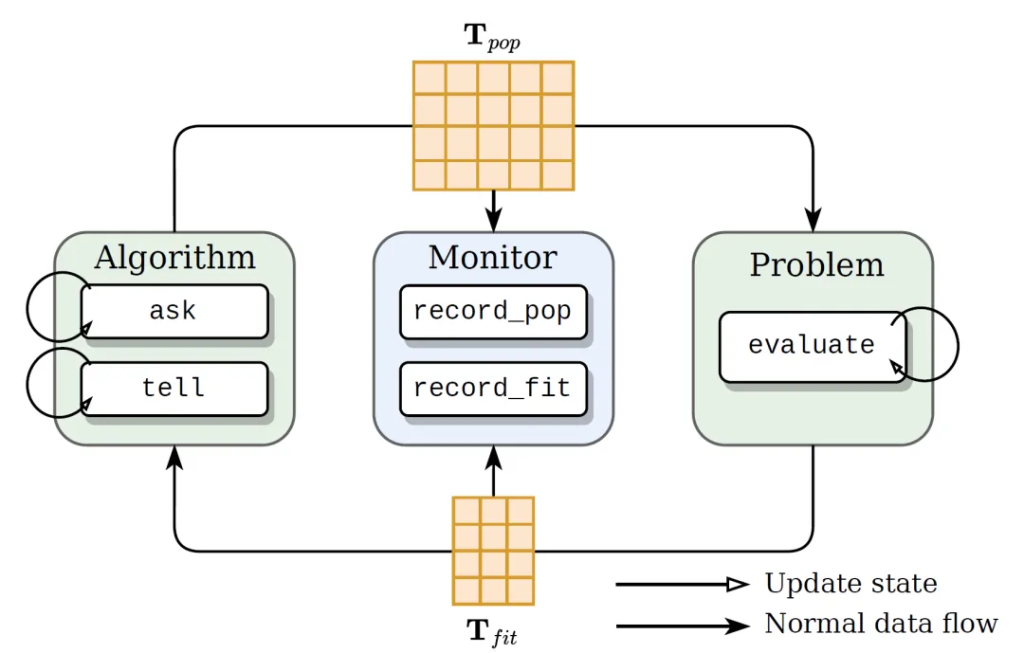
To achieve efficient acceleration of algorithms in a distributed GPU environment, EvoX adopts an innovative approach to abstract the evolutionary computation process as a tensorized dataflow. In our framework, EvoX breaks down the evolutionary computation process into three key parts: algorithm, problem, and monitor. This design allows each part to run independently and to manage and control its state through defined functions, greatly improving the flexibility and execution efficiency of the system. In addition, EvoX adopts a unified tensor data format to achieve information transmission between modules, which is the key to efficient GPU computing. Through this design, EvoX not only optimizes the data processing and transmission process but also provides a solid foundation for parallel execution and hardware acceleration of algorithms. Furthermore, all integrated evolutionary algorithms in EvoX are specially optimized to adapt to tensorized processing, ensuring that the algorithms can perform at maximum efficiency in a GPU-accelerated environment.
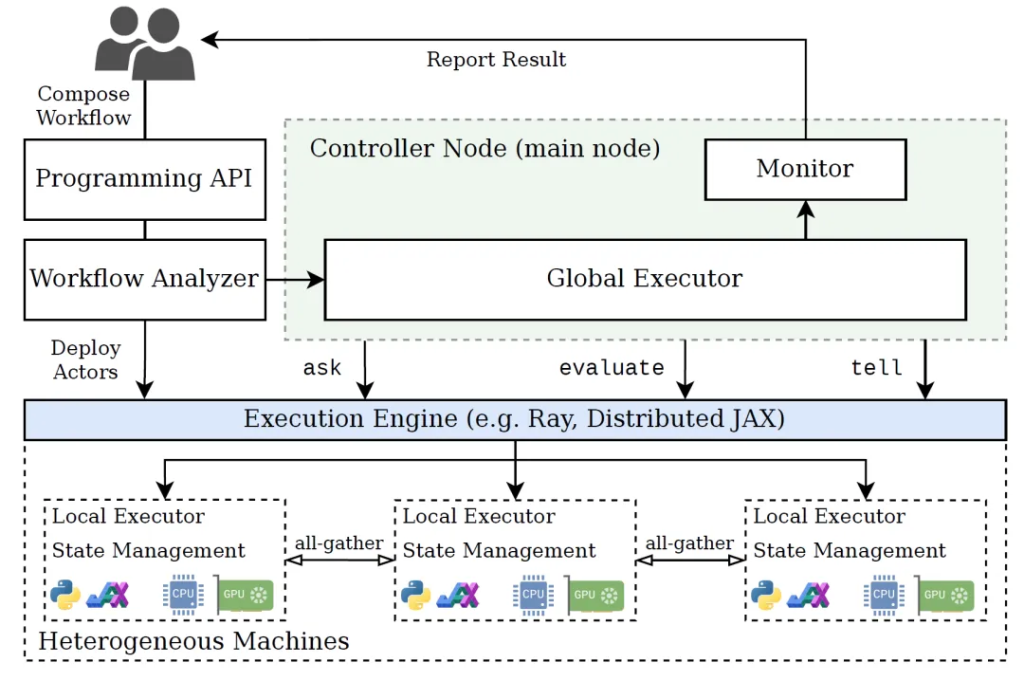
Thanks to its modular architecture, EvoX can break through the limitations of single-node execution environment and achieve comprehensive support for distributed cross-node operation. In distributed running mode, each node synchronizes data through an efficient network communication protocol to ensure the consistency and coordination of computing tasks. At the same time, EvoX introduces an innovative synchronization mechanism to significantly reduce the overhead of network communication, which is crucial for improving the overall performance of the system. The innovation of this synchronization strategy lies in the fact that it does not require any population data to be transmitted over the network, which greatly reduces the performance loss caused by communication latency. Therefore, EvoX can maintain excellent performance and response speed when dealing with distributed computing tasks involving large-scale data.
Programming Model
To enhance the user experience in efficiently implementing algorithms, EvoX has meticulously crafted a set of programming interfaces tailored specifically for evolutionary computation. This interface is not only easy to grasp and apply but also suits the unique needs of evolutionary algorithms.

EvoX’s programming interface adopts the principles of Python-based functional programming, enabling algorithm designers to focus their attention on the logical construction of algorithms rather than getting bogged down in maintaining program state and dealing with side effects of data operations. Concretely, EvoX’s programming interface allows algorithm developers to express the core components of evolutionary computation in a way that is easy to parallelize. This high-level abstraction significantly simplifies the complexity of algorithm implementation and makes algorithms more adaptable to parallel and distributed computing environments. Through this design approach, EvoX not only reduces the learning curve for users but also significantly improves the efficiency and flexibility of algorithm development. Developers can focus more on innovating and optimizing algorithm strategies without getting entangled in the intricacies of low-level implementation details.
Performance Showcase
Experimental data clearly demonstrates EvoX’s remarkable acceleration capabilities across key domains, including single-objective black-box optimization, multi-objective black-box optimization, and neuroevolution. Notably, EvoX’s performance gains are particularly pronounced when dealing with complex scenarios involving large populations or high-dimensional problems, with acceleration ratios exceeding a thousandfold in specific cases.
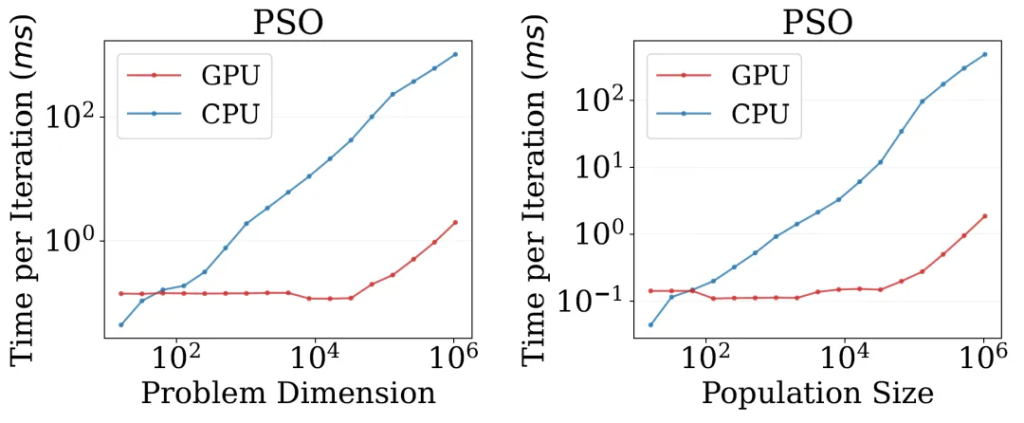
Consider the Particle Swarm Optimization (PSO) algorithm in single-objective black-box optimization. Leveraging an RTX 3090 GPU, EvoX evaluates the performance of one million candidate solutions in a mere millisecond. This groundbreaking advancement implies that evolutionary computation tasks that might have taken days to complete can now be achieved within minutes with EvoX.
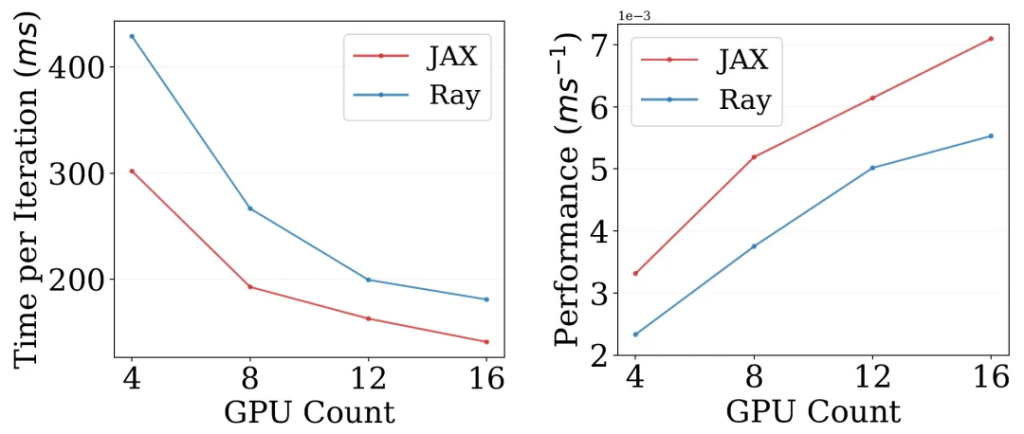
For cross-node distributed computing acceleration, EvoX offers two frameworks: JAX and Ray. Performance testing was conducted on a four-node cluster, each node equipped with four GPUs. The results revealed that both frameworks exhibited near-linear speedups in the distributed environment. Remarkably, EvoX’s distributed acceleration support is fully automated, eliminating the need for users to write any additional engineering code to reap the benefits of distributed computing.
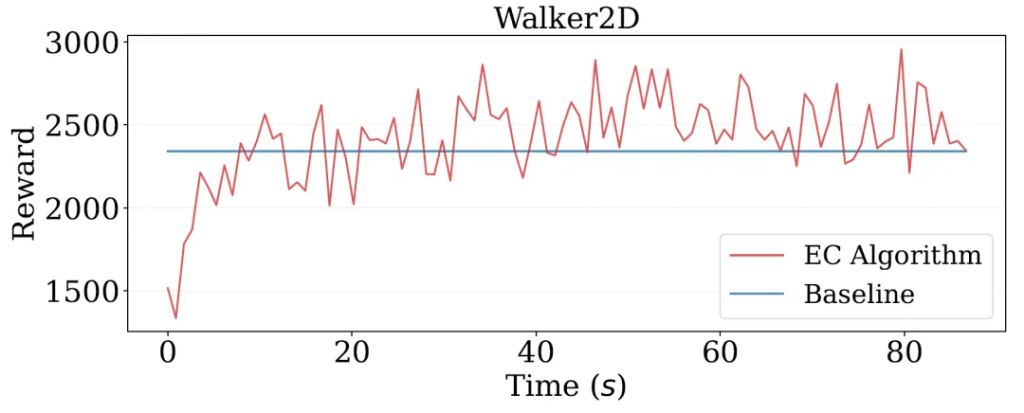
EvoX excels not only in benchmark tests but also in neuroevolution tasks executed on the Brax platform. Specifically, in the Walker2D environment, the CMA-ES algorithm achieved a reward value comparable to the PPO2 algorithm in a mere 10 seconds. Additionally, EvoX provides native support for various reinforcement learning environments, including Brax, Gym, and EnvPool. It further integrates over a hundred deep learning datasets through TensorFlow-Datasets, providing a solid data foundation for users’ research and development.
Citing EvoX
@article{evox,
title = {{EvoX}: {A} {Distributed} {GPU}-accelerated {Framework} for {Scalable} {Evolutionary} {Computation}},
author = {Huang, Beichen and Cheng, Ran and Li, Zhuozhao and Jin, Yaochu and Tan, Kay Chen},
journal = {IEEE Transactions on Evolutionary Computation},
year = 2024,
doi = {10.1109/TEVC.2024.3388550}
}