![[IEEE TNNLS] RelativeNAS: Relative Neural Architecture Search via Slow-Fast Learning](https://www.emigroup.tech/wp-content/uploads/2021/07/RelativeNAS.png)
Hao Tan, Ran Cheng*, et al.
Abstract:
Despite the remarkable success of convolutional neural networks (CNNs) in computer vision, it is time-consuming and error-prone to manually design a CNN. Among various neural architecture search (NAS) methods that are motivated to automate designs of high-performance CNNs, the differentiable NAS and population-based NAS are attracting increasing interests due to their unique characters. To benefit from the merits while overcoming the deficiencies of both, this work progresses a novel NAS method, RelativeNAS. As the key to efficient search, RelativeNAS performs joint learning between fast learners (i.e., decoded networks with relatively lower loss value) and slow learners in a pairwise manner. Moreover, since RelativeNAS only requires low-fidelity performance estimation to distinguish each pair of fast learner and slow learner, it saves certain computation costs for training the candidate architectures. The proposed RelativeNAS brings several unique advantages: 1) it achieves state-of-the-art performances on ImageNet with top-1 error rate of 24.88%, that is outperforming DARTS and AmoebaNet-B by 1.82% and 1.12%, respectively; 2) it spends only 9 hours with a single 1080Ti GPU to obtain the discovered cells, that is, 3.75x and 7875x faster than DARTS and AmoebaNet, respectively; and 3) it directly transferred to object detection, semantic segmentation, and keypoint detection, yielding competitive results of 73.1% mAP on PASCAL VOC, 78.1% mIoU on Cityscapes, and 68.5% AP on MSCOCO, respectively. [Source Code]
Results
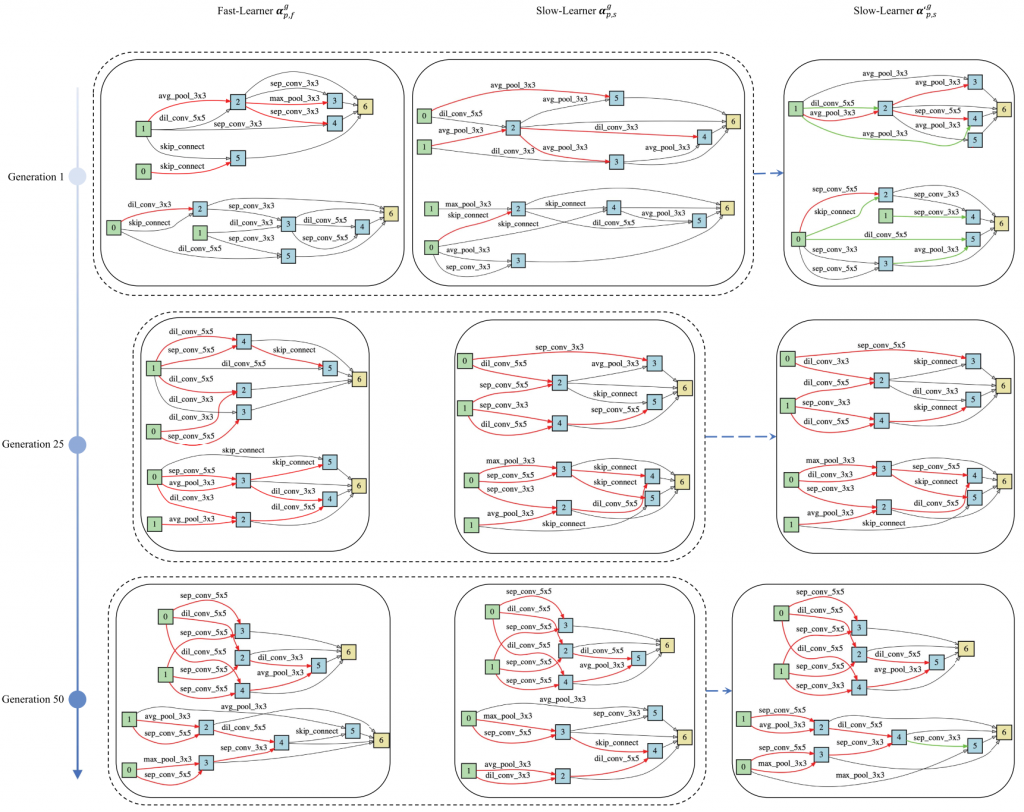
Figure 1: Illustration of the slow-fast learning with decoded architectures at generations 1, 25, and 50 respectively. A slow learner updates its connections and operations by learning from a fast learner. The red lines denote the common connection between the fast learner and the slow learner, and the green lines denote the new connections after learning.
Performance on CIFAR10
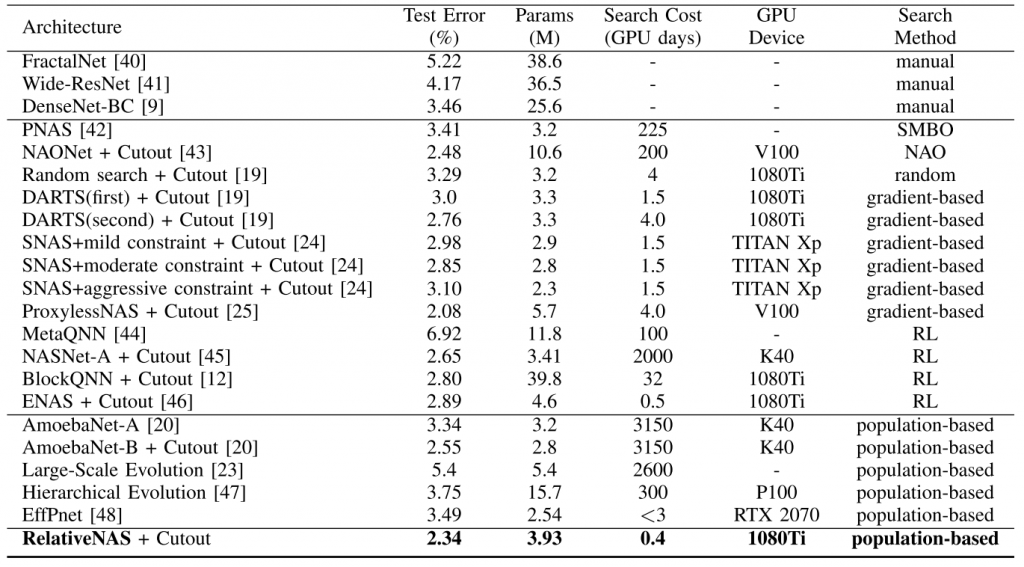
Table 1: Comparisons with other state-of-the-art methods on CIFAR-10
Performance on ImageNet
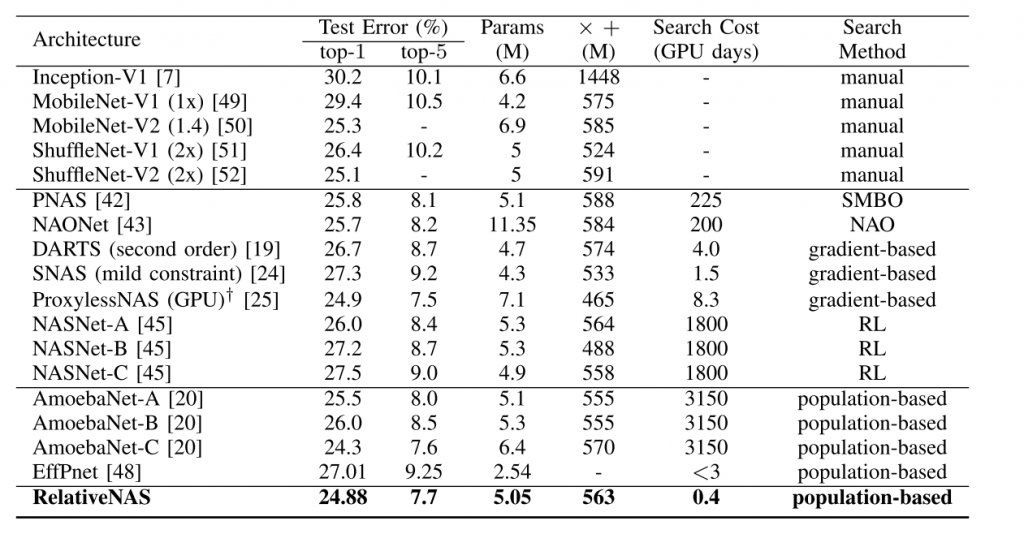
Table 2: Comparisons with other state-of-the-art methods on ImageNet. All compared NAS methods are searched on CIFAR-10 except the ProxylessNAS (GPU) which is searched on ImageNet directly.
Performance on PASCAL VOC
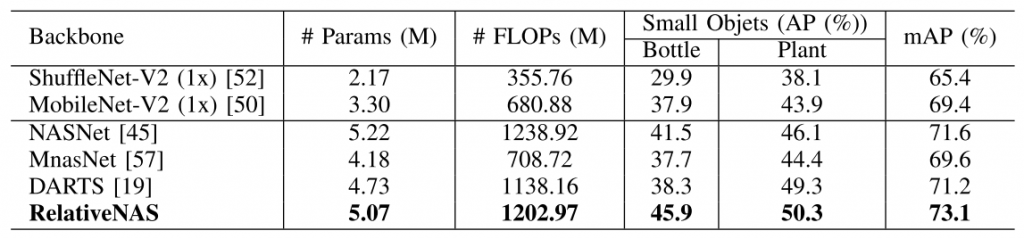
Table 3: Results of SSDLite with different mobile-setting backbones on PASCAL VOC 2007 test set.
Performance on Cityscapes
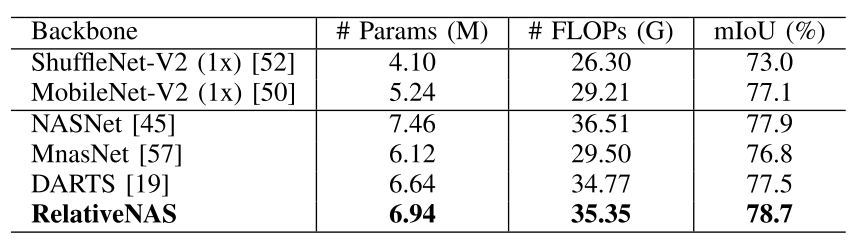
Table 4: Results of BiSeNet with different mobile-setting backbones on Cityscapes validation set (single scale and no flipping).
Performance on MS COCO 2017
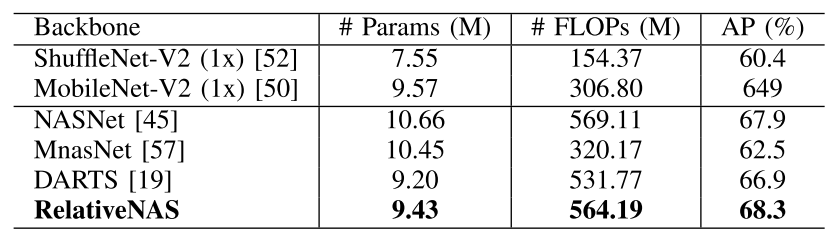
Table 5: Results of SimpleBaseline with different mobile-setting backbones on MS COCO 2017 validation set.
Acknowledgement
We thank Zhichao Lu for his comments and support on this article. We thank National Science Foundation of China under Grant 61903178, Grant 61906081, and Grant U20A20306; the Shenzhen Science and Technology Program under Grant RCBS20200714114817264; the Program for Guangdong Introducing Innovative and Entrepreneurial Teams under Grant 2017ZT07X386; the Program for University Key Laboratory of Guangdong Province under Grant 2017KSYS008; and the General Research Fund of Hong Kong under Grant 27208720.
Bibtex
Please cite our work if you find this helps your research.
@ARTICLE{
9488309,
author={Tan, Hao and Cheng, Ran and Huang, Shihua and He, Cheng and Qiu, Changxiao and Yang, Fan and Luo, Ping},
journal={IEEE Transactions on Neural Networks and Learning Systems},
title={RelativeNAS: Relative Neural Architecture Search via Slow-Fast Learning}, year={2021},
doi={10.1109/TNNLS.2021.3096658}
}