![[IEEE ToG] Lamarckian Platform: Pushing the Boundaries of Evolutionary Reinforcement Learning towards Asynchronous Commercial Games](https://www.emigroup.tech/wp-content/uploads/2022/09/未命名图片-840x420.png)
Hui Bai, Ruimin Shen, Yue Lin, Botian Xu, and Ran Cheng*
Abstract:
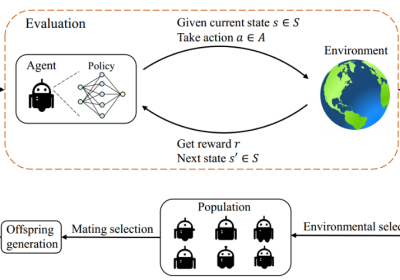
Despite the emerging progress of integrating evolutionary computation into reinforcement learning, the absence of a high-performance platform endowing composability and massive parallelism causes non-trivial difficulties for research and applications related to asynchronous commercial games. Here we introduce Lamarckian – an open-source platform featuring support for evolutionary reinforcement learning scalable to distributed computing resources. To improve the training speed and data efficiency, Lamarckian adopts optimized communication methods and an asynchronous evolutionary reinforcement learning workflow. To meet the demand for an asynchronous interface by commercial games and various methods, Lamarckian tailors an asynchronous Markov Decision Process interface and designs an object-oriented software architecture with decoupled modules. In comparison with the state-of-the-art RLlib, we empirically demonstrate the unique advantages of Lamarckian on benchmark tests with up to 6000 CPU cores: i) both the sampling efficiency and training speed are doubled when running PPO on Google football game; ii) the training speed is 13 times faster when running PBT+PPO on Pong game. Moreover, we also present two use cases: i) how Lamarckian is applied to generating behavior-diverse game AI; ii) how Lamarckian is applied to game balancing tests for an asynchronous commercial game. [Github: https://github.com/lamarckian/lamarckian]
Results:
Performance:
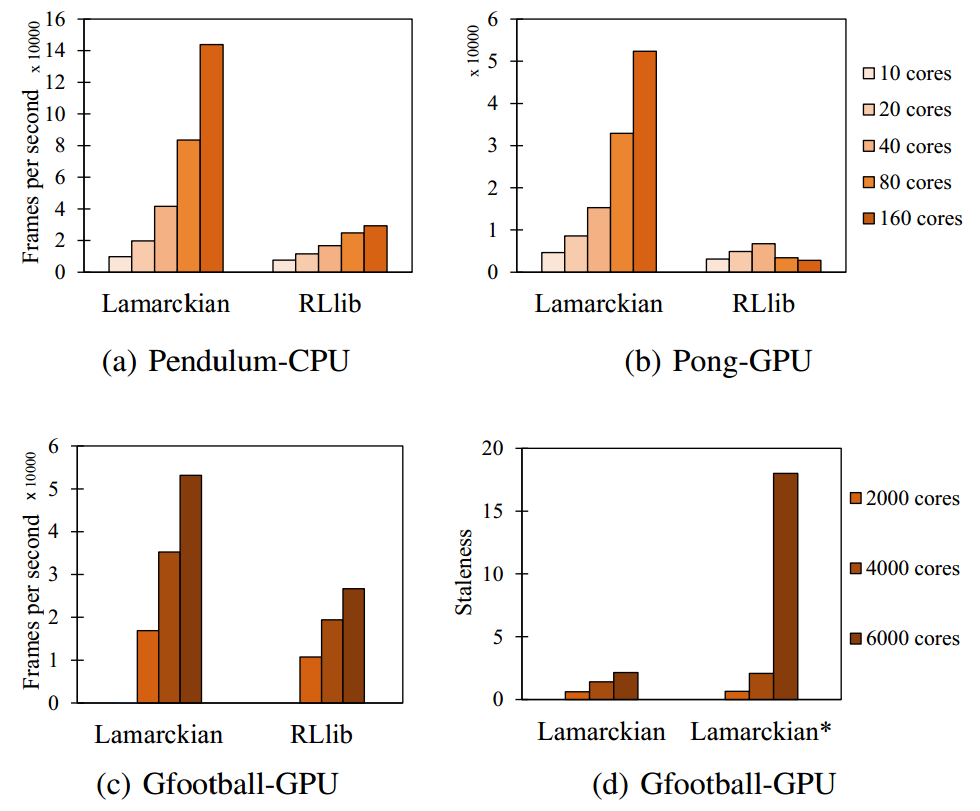
Fig.1. Sampling efficiency of Lamarckian scales nearly linearly both on small-scale (10 to 160 CPU cores) and large-scale (2000 to 6000 CPU cores) training instances, which is only true for RLlib in (a) and (c). Besides, the staleness metric of Lamarckian* in (d) sharply increases as the number of CPUs grows.
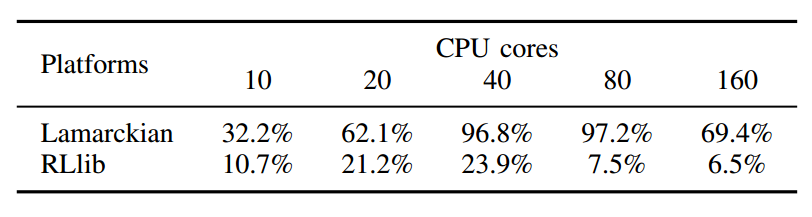
Table 1. The average CPU utilization of Lamarckian and RLlib when running PPO on image Pong.
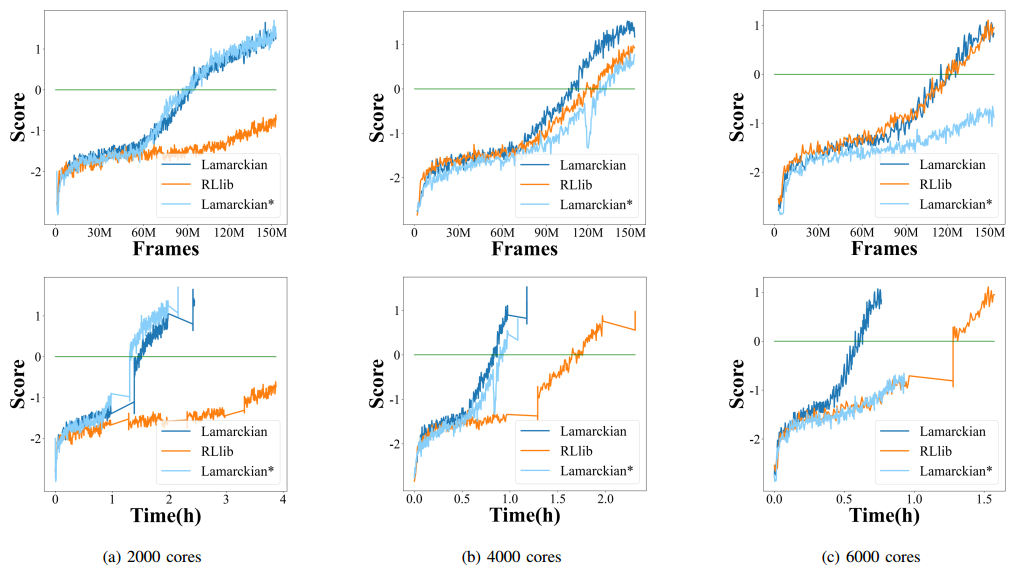
Fig. 2. The agents’ performance and the training speed of Lamarckian, RLlib and Lamarckian* by the learning curves in 150M environment frames when running PPO on Gfootball.
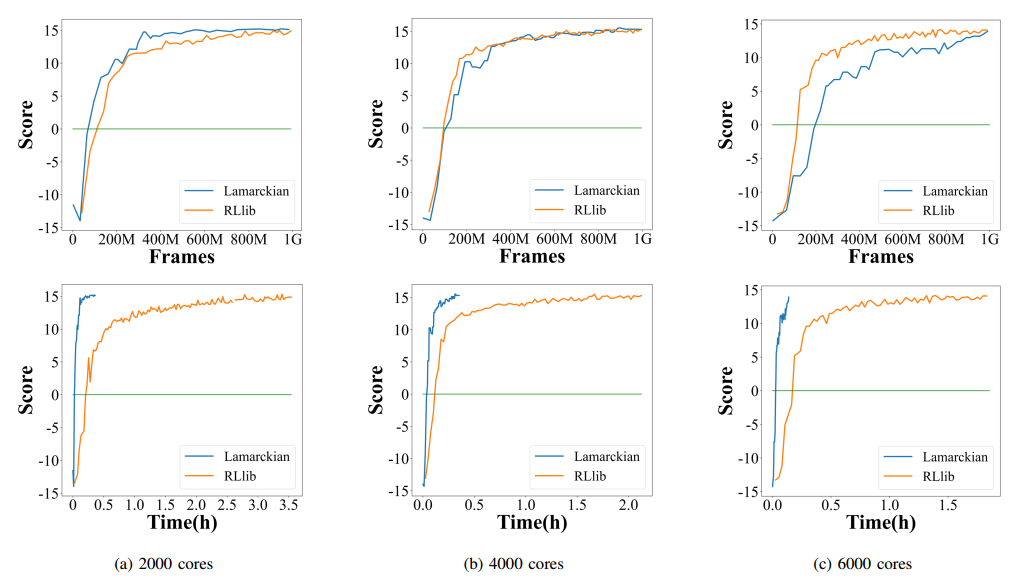
Fig. 3. The agents’ performance and the training speed of Lamarckian and RLlib by the learning curves in 1G environment frames when running PBT+PPO on Pong.
Use case: Game Balancing in RTS Game

Fig.4. (a) is a typical hero-led fighting arena of The Lord of the Rings: Rise to War. (b) is the final solution set obtained by Lamarckian to a three-objective optimization problem in the game balancing test. f1 is the battle damage difference, f2 is the remaining economic resources multiples, and f3 is the strength of the weakest team.
Acknowledgements:
This work was supported by the National Natural Science Foundation of China (No. 61906081), the Shenzhen Science and Technology Program (No. RCBS20200714114817264), the Guangdong Provincial Key Laboratory (No.2020B121201001), and the Program for Guangdong Introducing Innovative and Entrepreneurial Teams (Grant No. 2017ZT07X386).
Citation
@ARTICLE{
author={Hui Bai, Ruimin Shen, Yue Lin, Botian Xu, and Ran Cheng},
journal={IEEE Transactions on Games},
title={Lamarckian Platform: Pushing the Boundaries of Evolutionary Reinforcement Learning towards Asynchronous Commercial Games},
year={2022}}