![[ICML 2022] VLMixer: Unpaired Vision-Language Pre-training via Cross-Modal CutMix](https://www.emigroup.tech/wp-content/uploads/2022/06/1_副本-3-840x420.png)
Teng Wang et al.
Abstract:
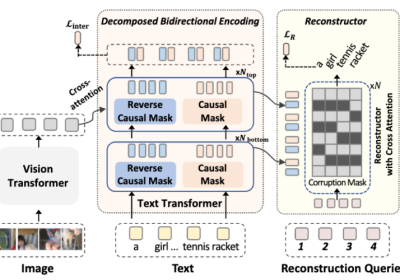
Existing vision-language pre-training (VLP) methods primarily rely on paired image-text datasets, which are either annotated by enormous human labors, or crawled from the internet followed by elaborate data cleaning techniques. To reduce the dependency on well-aligned imagetext pairs, it is promising to directly leverage the large-scale text-only and image-only corpora. This paper proposes a data augmentation method, namely cross-modal CutMix (CMC), for implicit cross-modal alignment learning in unpaired VLP. Specifically, CMC transforms natural sentences from the textual view into a multi-modal view, where visually-grounded words in a sentence are randomly replaced by diverse image patches with similar semantics. There are several appealing proprieties of the proposed CMC. First, it enhances the data diversity while keeping the semantic meaning intact for tackling problems where the aligned data are scarce; Second, by attaching cross-modal noise on uni-modal data, it guides models to learn token-level interactions across modalities for better denoising. Furthermore, we present a new unpaired VLP method, dubbed as VLMixer, that integrates CMC with contrastive learning to pull together the uni-modal and multi-modal views for better instance-level alignments among different modalities. Extensive experiments on five downstream tasks show that VLMixer could surpass previous state-of-the-art unpaired VLP methods [Source Code (coming soon)].
Results:
Overall Performance
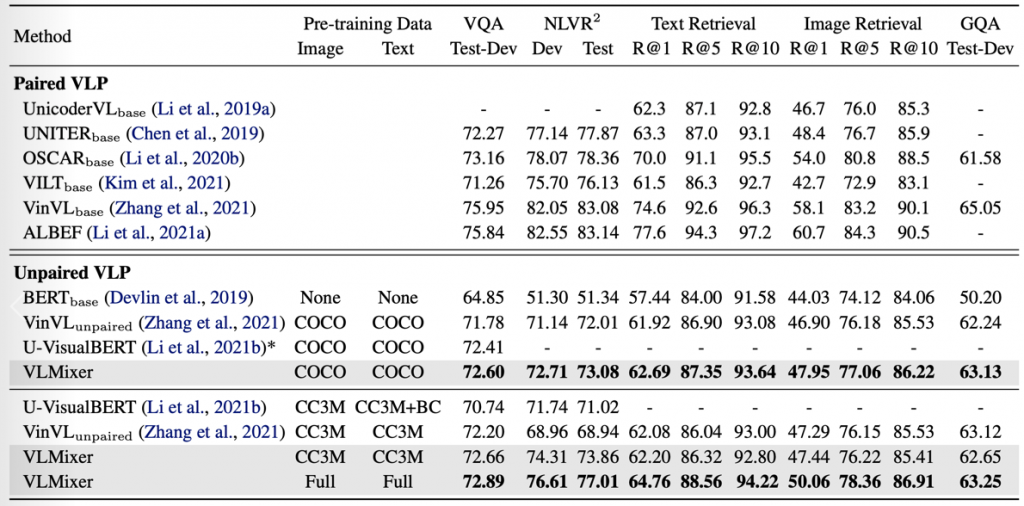
Table 1: Comparison with state-of-the-art unpaired VLP methods. We list the performance of paired VLP methods for reference.
Comparison of Pretraining Objectives
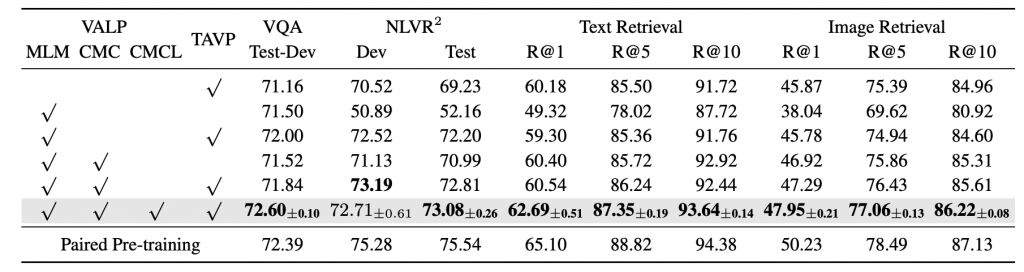
Table 2: Ablation studies of different pre-training objectives. All models are pre-trained on COCO without alignment information except in the last row.
Influence of the Concept Number
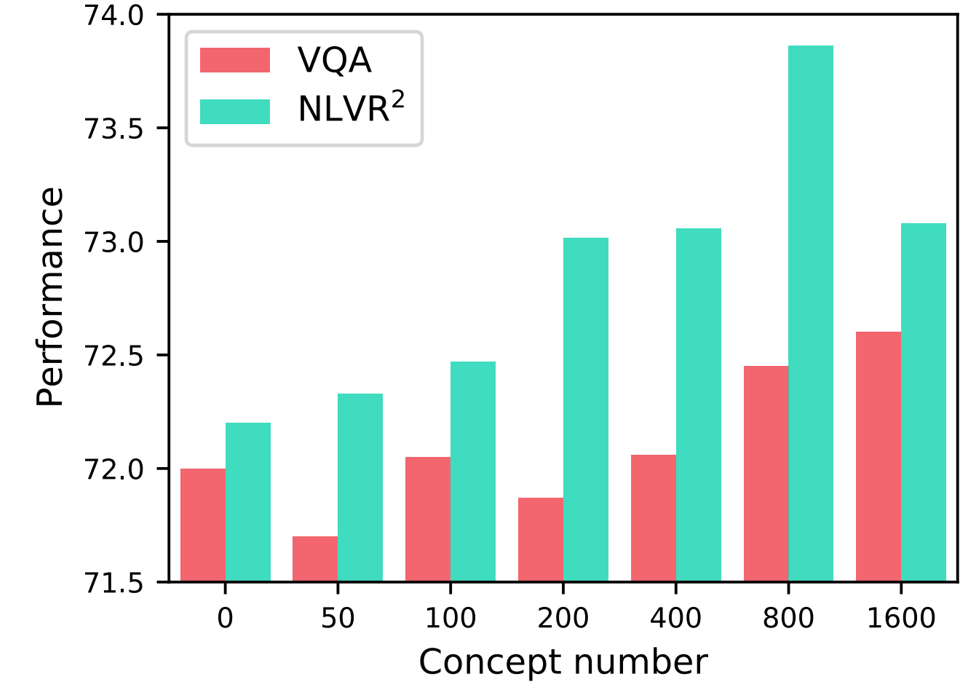
Figure 1: The downstream performance using different number of concepts in the patch gallery.
Comparison of Contrastive Learning Methods
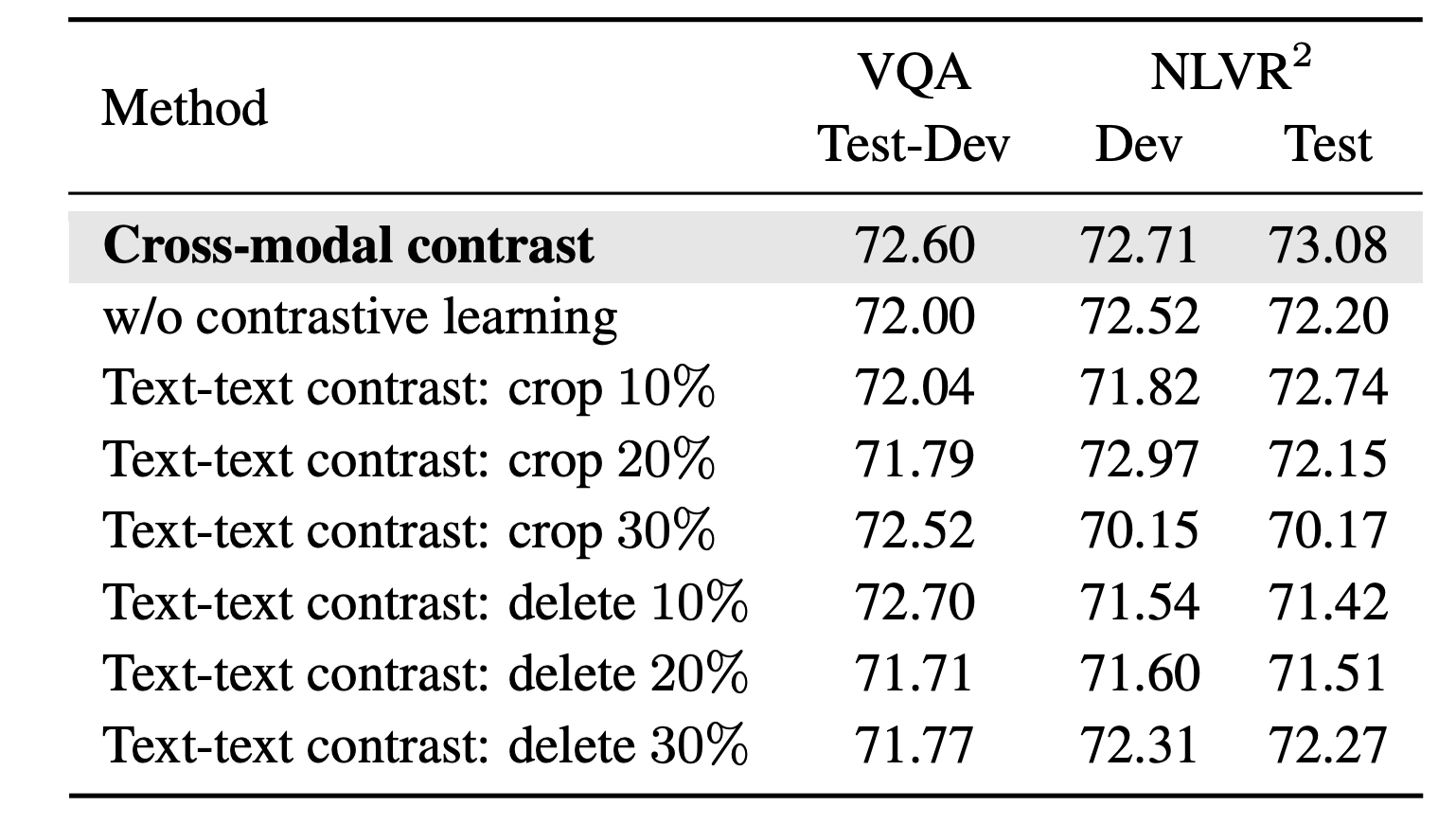
Table 3: Ablation study of the contrastive learning methods and data augmentations.
Acknowledgments:
This work is supported by the National Natural Science Foundation of China under Grant No. 61972188, No. 62122035, No. 61906081, No. 62106097, the General Research Fund of HK No. 27208720, 17212120, and the China Postdoctoral Science Foundation (2021M691424).
Citation
@ARTICLE{wang2022vlmixer,
author={Wang, Teng and Jiang, Wenhao and Lu, Zhichao and Zheng, Feng and Cheng, Ran and Yin, Chengguo and Luo, Ping},
journal={arXiv preprint},
title={VLMixer: Unpaired Vision-Language Pre-training via Cross-Modal CutMix},
year={2022}
}